Table of Contents
Teaching quadrotor unmanned aerial vehicles (UAVs) to fly autonomously is a high-stakes engineering hurdle. Because quadrotors are inherently unstable and exhibit complex, non-linear dynamics, training them using standard model-free Reinforcement Learning (RL) is notoriously data-intensive and risky. In a typical RL setup, an agent must experience thousands of “crashes” in simulation to learn basic stability, a process that is often computationally expensive and unsafe.
Standard multilayer perceptron (MLP)-based RL models often treat every new orientation or position as a completely unique configuration, requiring the RL agent to learn all information from scratch. To address this, this study introduces Equivariant Reinforcement Learning. This framework uses geometric principles to make learning significantly faster and more robust by embedding the invariance and equivariance properties directly into the neural network architecture.
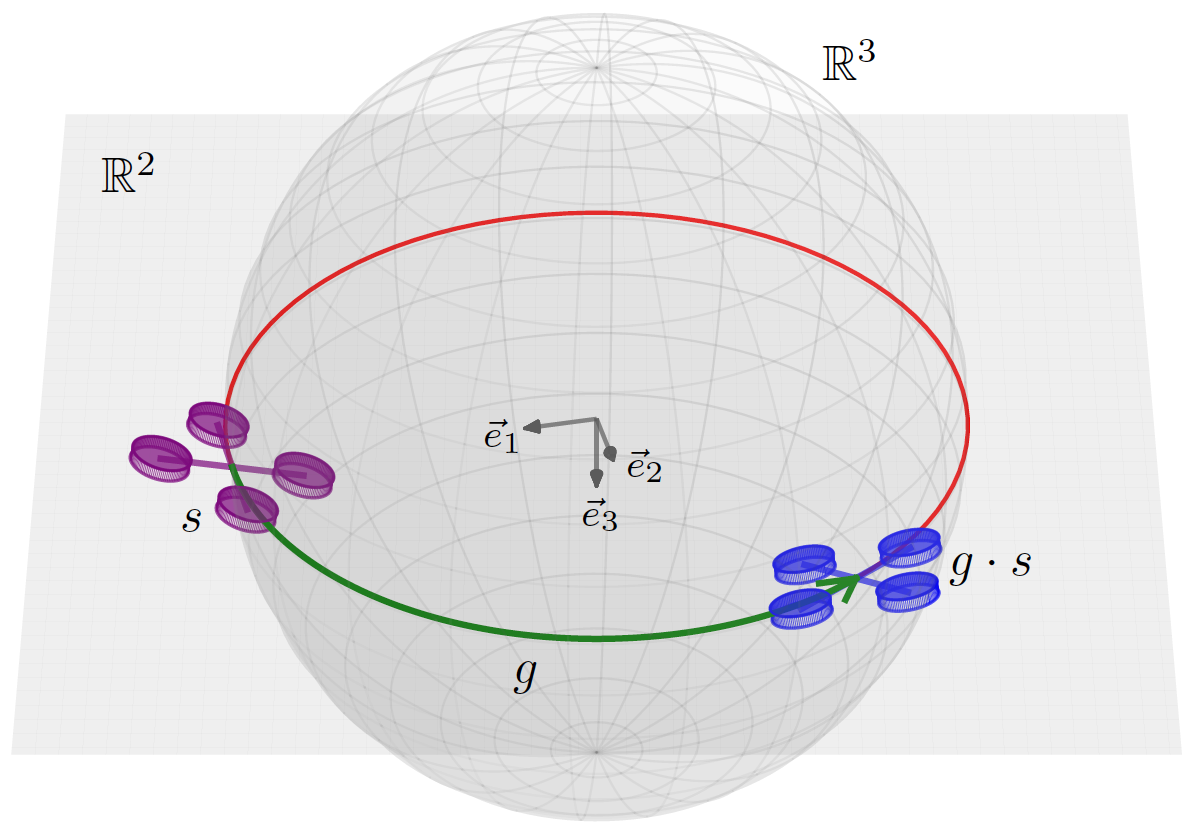
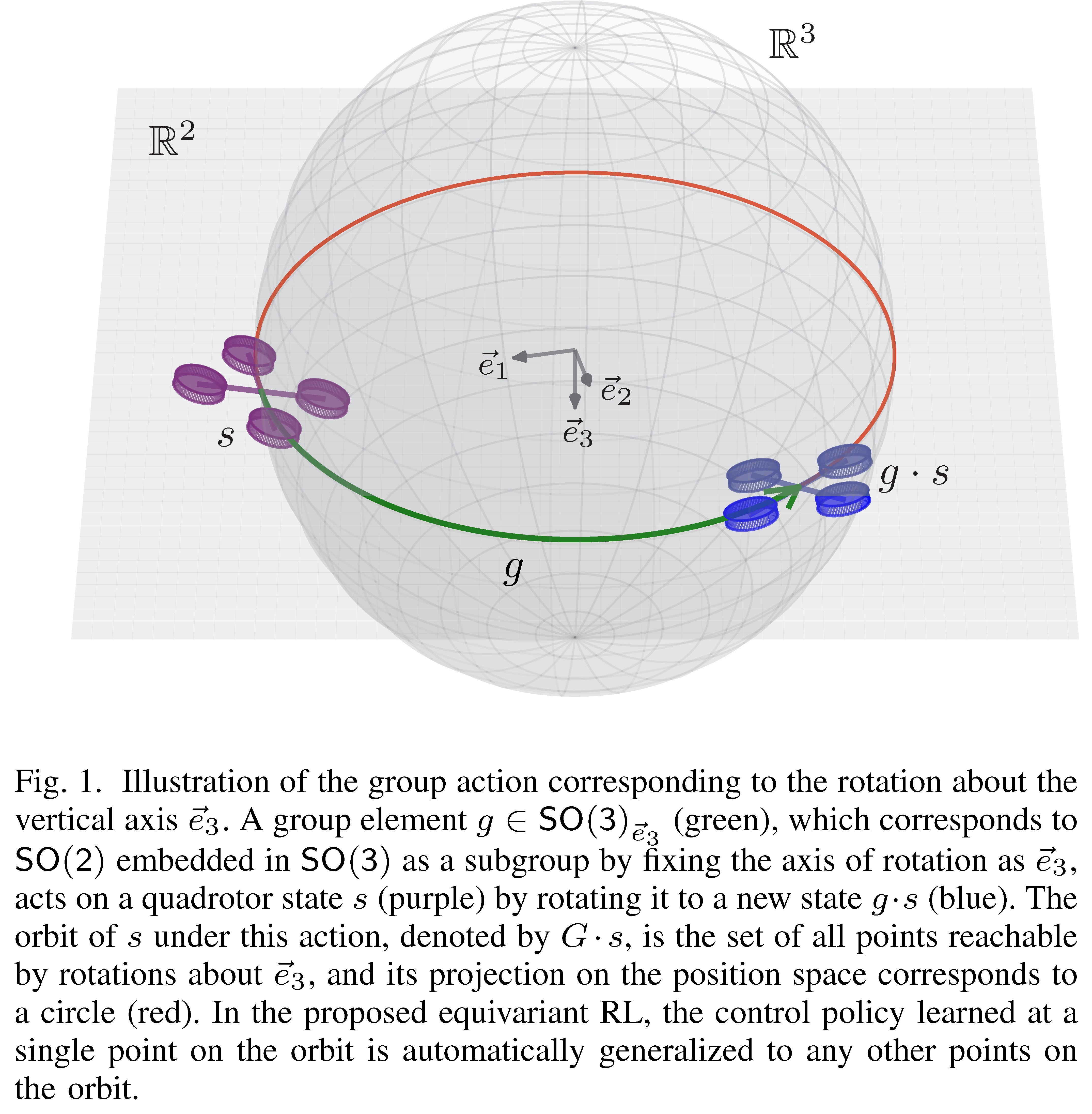
Geometry as a Shortcut: The Power of Equivariance
The breakthrough in this research lies in identifying rotational and reflectional symmetries present in the quadrotor dynamics. By using Equivariant Multilayer Perceptrons (EMLPs), the drone can learn an optimal control action in one configuration and automatically apply it to others.
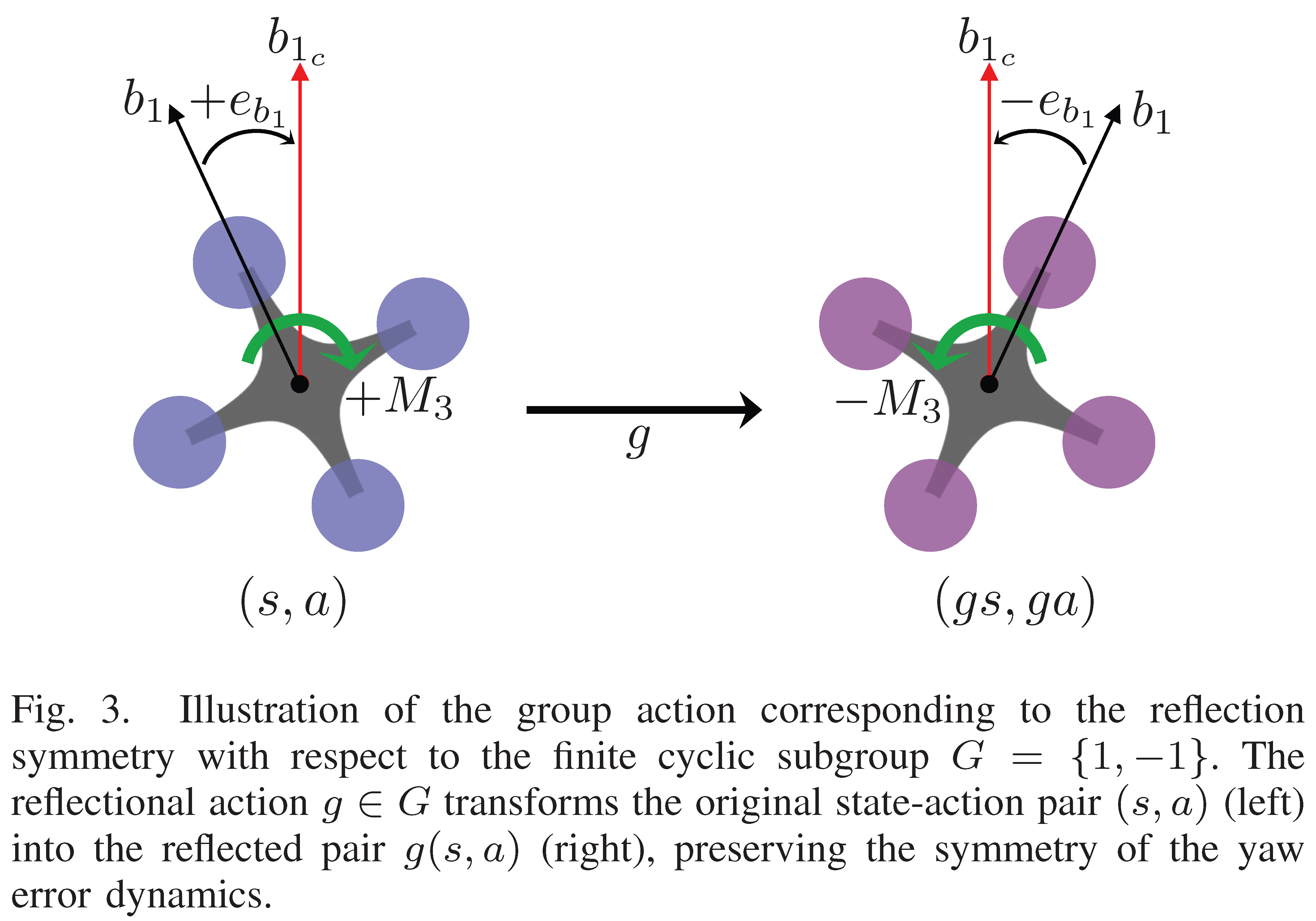
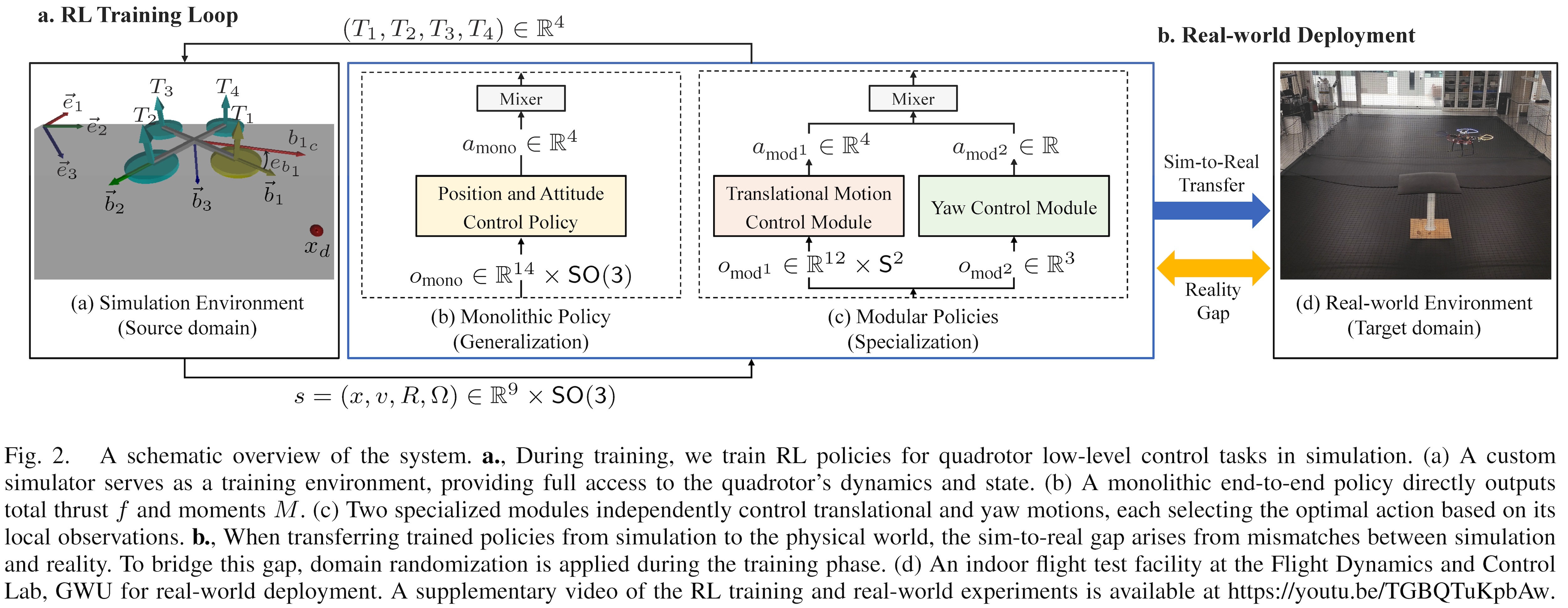
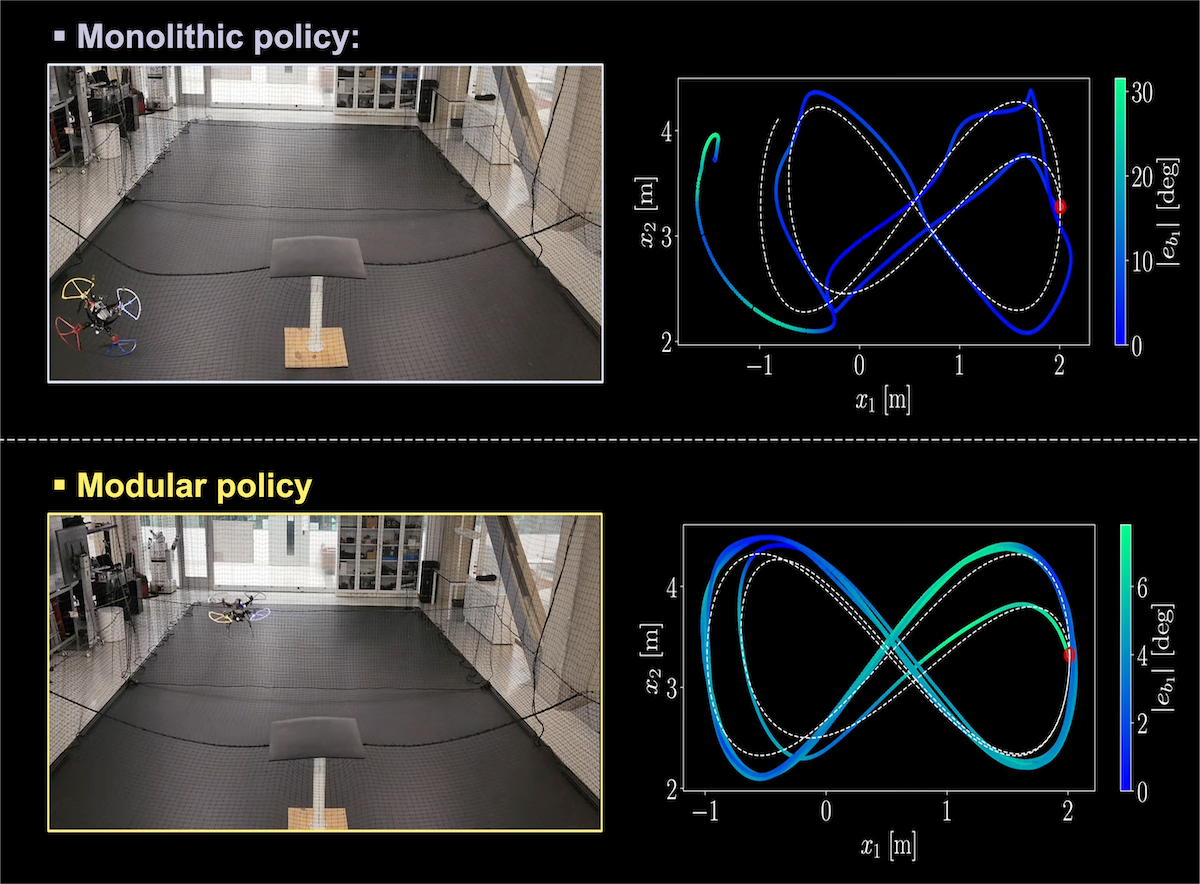
Two Brains are Better Than One: Modular vs. Monolithic
A core strategic insight of this work is the move away from “monolithic” (single-agent) brains toward specialized “modular” (multi-agent) architectures.
| Feature | Monolithic (Mono-MLP/EMLP) | Modular (Mod-MLP/EMLP) |
| Structure | Single agent manages all flight aspects. | Decoupled: Translation and Yaw modules. |
| Geometry | Operates on the full $SO(3)$ group. | Splits $SO(3)$ into $S^2$ (thrust) and $S^1$ (yaw). |
| Efficiency | Slower convergence; prone to overfitting. | Parallelized learning; superior tracking. |
| Sample Requirement | Still struggling at $8 \times 10^5$ timesteps. | Near-peak rewards within $\approx 2 \times 10^5$ timesteps. |
By splitting the three-dimensional orthogonal group $SO(3)$ into a sphere ($S^2$) for translational control and a circle ($S^1$) for yaw control, the modular approach prevents performance degradation during agile maneuvers. As evidenced by learning curves, the Mod-EMLP architecture achieves significantly higher returns early in the training phase compared to any other framework.
Zero-Shot Sim-to-Real Transfer Validation
A major hurdle in robotics is “Sim-to-Real” transfer. To bridge this, this work utilized Domain Randomization, where physical parameters–such as mass, arm length, and inertia–were uniformly sampled within $\pm 10\%$ of their nominal values during training. This forces the policy to be robust rather than environment-specific.
The framework was validated through a Zero-Shot Transfer process, and the experimental setup at the Flight Dynamics and Control Lab included:
- Vicon Valkyrie VK-8 Motion Capture: A 12-camera system running at 200 Hz for precise position and attitude estimation.
- NVIDIA Jetson TX2: An onboard flight computer managing the RL controller and EKF state estimation in real-time.
Analysis of figure-eight Lissajous trajectory flight tests shows that incorporating equivariant learning within a modular design is the key:
| Metric | Monolithic MLP (Baseline) | Modular EMLP (Winner) |
| Average Position Error | 14.63 cm | 8.44 cm (Nearly 42% reduction) |
| Average Yaw Error | 7.15 degrees | 4.33 degrees (Highly precise) |
| Generalization | Must manually learn every configuration, leading to redundancies in learning. | Encodes rotational/reflectional symmetry for 10x more efficient learning. |
The Future of Geometric Learning in Robotics
While this study utilized quadrotors, these geometric RL methods are a blueprint for any robotics system with underlying symmetries, from bipedal robots to industrial manipulators. Now we must ask:
If we can eliminate the redundancy of learning through geometric priors, are we finally moving toward an era of “Near-Zero-Data” robotics where physics-informed architectures replace brute-force computation?
For a detailed look at the study, check out the research publication and explore the open-source training code.

{kind=link}
Start the conversation